When should I book my room on Hotel Tonight?

Somehow, I’ve always liked the idea of Hotel Tonight. For those who don’t know about Hotel Tonight, it’s an app where you can book last-second hotel rooms. The idea revolves around the perishability of hotel rooms and Revenue Managers wanting to increase RevPAR (Revenue Per Available Room). Hotel Tonight has been quite successful, so much in fact that it was acquired by Airbnb for $400 Million.
Whenever I’m travelling last second and know I’ll need a room, I tend to go for Hotel Tonight. But I always wonder how long I should wait to book? Should I wait as long as possible? Should I book now, to make sure I’ll definitely get a room? During the day I’ll reload the app various times, but completely forget what the previous prices were. So I decided to use my free 1H compute power on scrapinghub to get some data on the matter.
I made a simple (extremely simple) scrapy spider to scrape the prices for hotels in Lisbon, listed on Hotel Tonight:
import scrapy
class ht_spider(scrapy.Spider):
name = "ht"
def start_requests(self):
urls = [
"https://www.hoteltonight.com/s/lisbon-pt"
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
for listing in response.css(".mainDetailsWrapper_sx8sj8"):
yield {
'hotel_name': listing.css(".hotelName_b9i185::text").extract(),
'price': listing.css("div:nth-child(1) > span:nth-child(1) > span:nth-child(1)::text").extract()
}
I then used my free hour of compute on scrapinghub, to run the spider every hour from Monday to Friday. It’s not quite “Big Data”, but it’s what my free hour of compute got me :)
My hypothesis was that prices would gradually decrease. I assumed that most hotels manage HotelTonight manually (as I’ve experienced working as a receptionist sometime in a previous life), meaning that a revenue manager would likely update prices once in the morning based on availability, in the afternoon depending on bookings on the day, and lastly in the evening before ending their shift.
Well, let’s look at the data.
Over the 5 days there were 37 different hotels on the website - not bad for a small city like Lisbon! However, because I’m lazy and to make things easier I just plotted for the 10 most frequent hotels listed, which are:
- Pousada de Lisboa
- My Story Hotel Tejo
- Hello Lisbon Santos Apartments
- My Story Charming Hotel Augusta
- Santiago de Alfama Boutique Hotel
- Vincci Liberdade
- Hotel do Chiado
- Hotel Lis
- The Art Inn Lisbon
- The 8 DownTown Suites
Here are the plotted prices over the week:
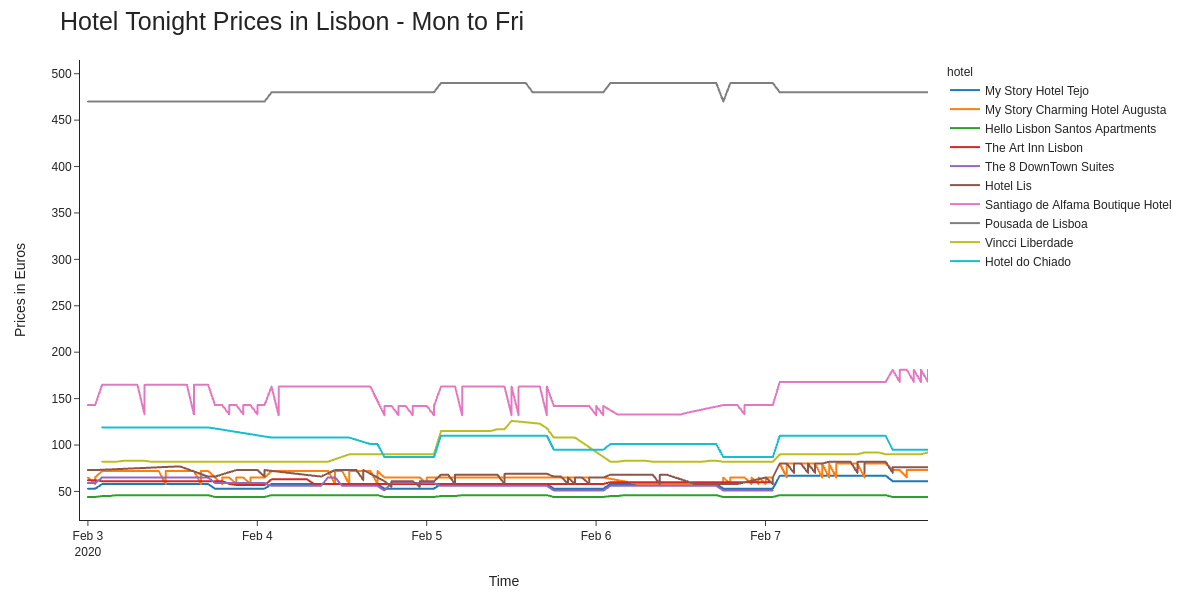
There are definitely some observable patterns in the data, but that fancy hotel skews all the rest of the data. When removing the €470 a night room (hey - it does include free breakfast at least), we already get a better view of the data:
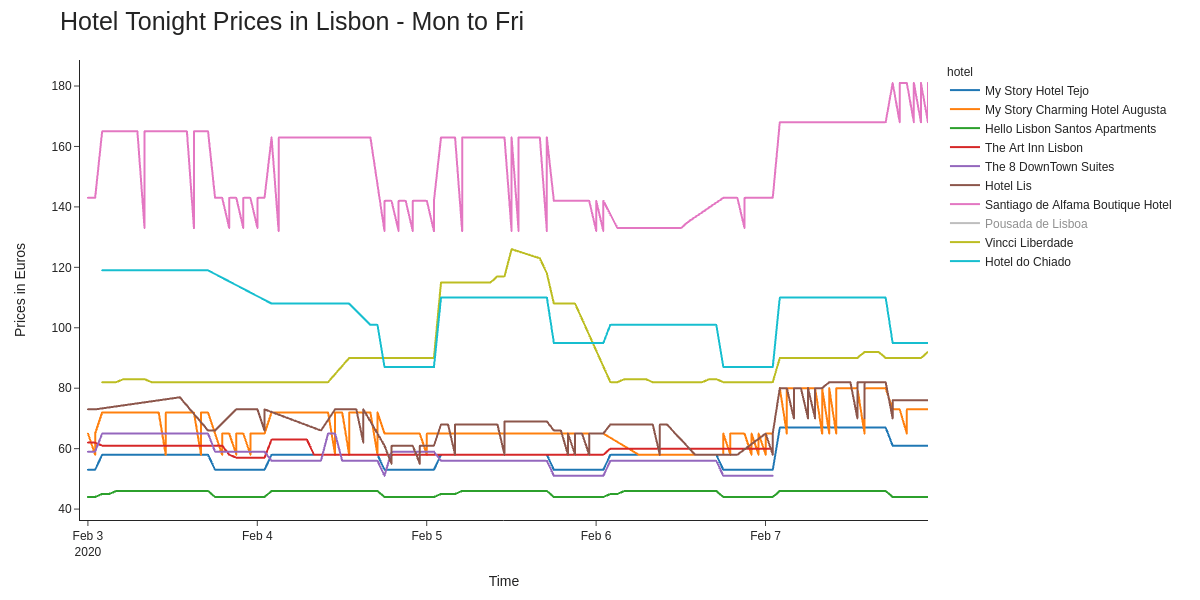
Daily breakdown:
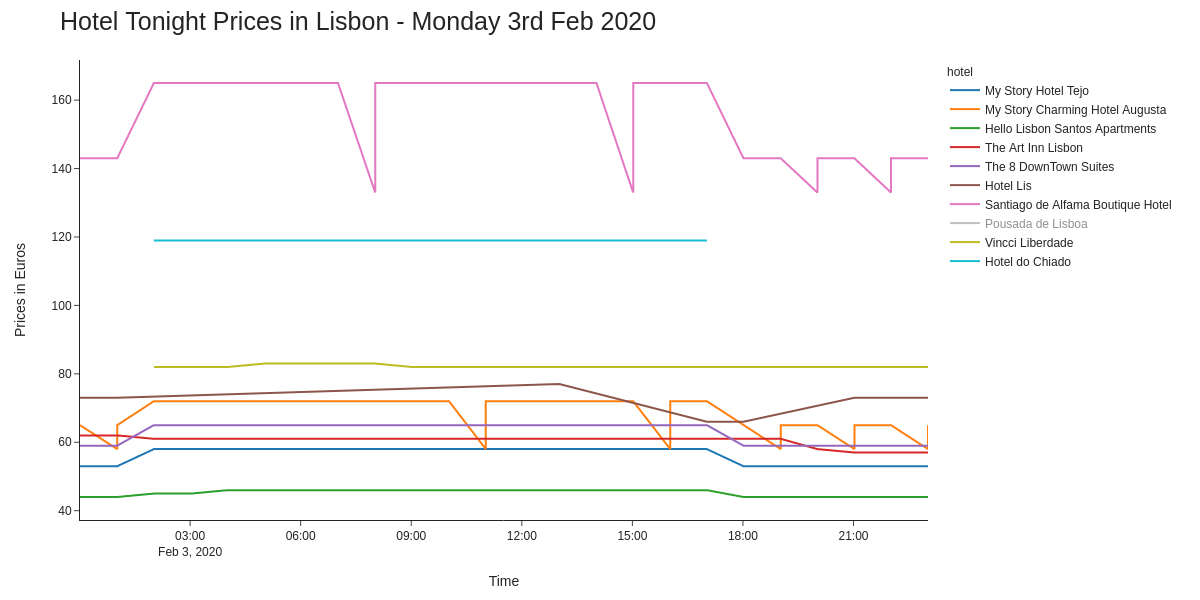
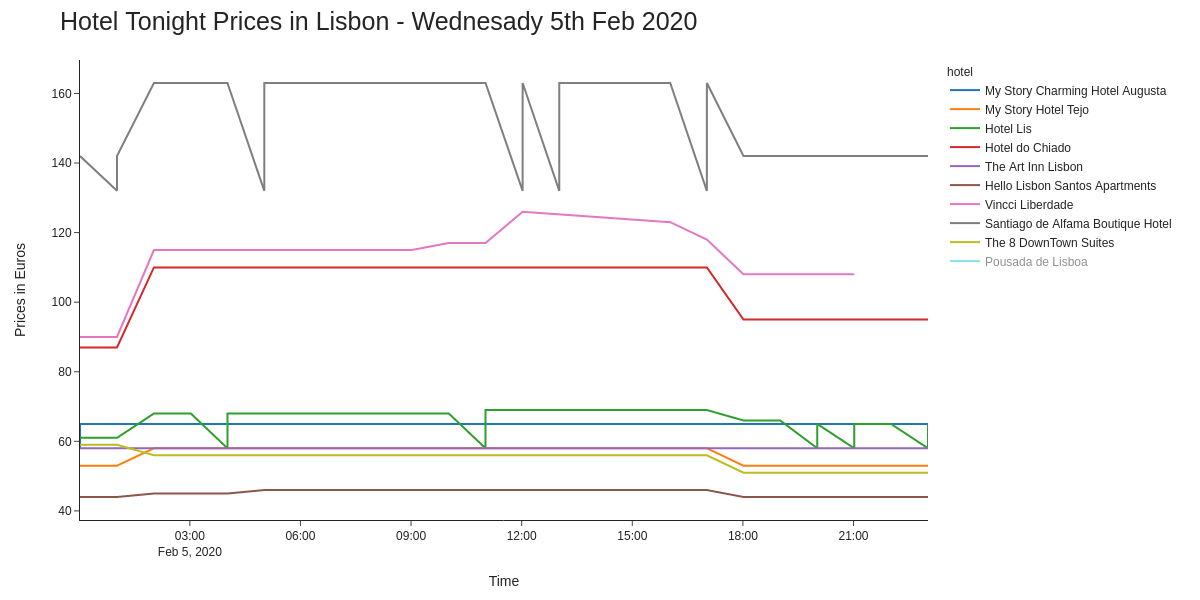
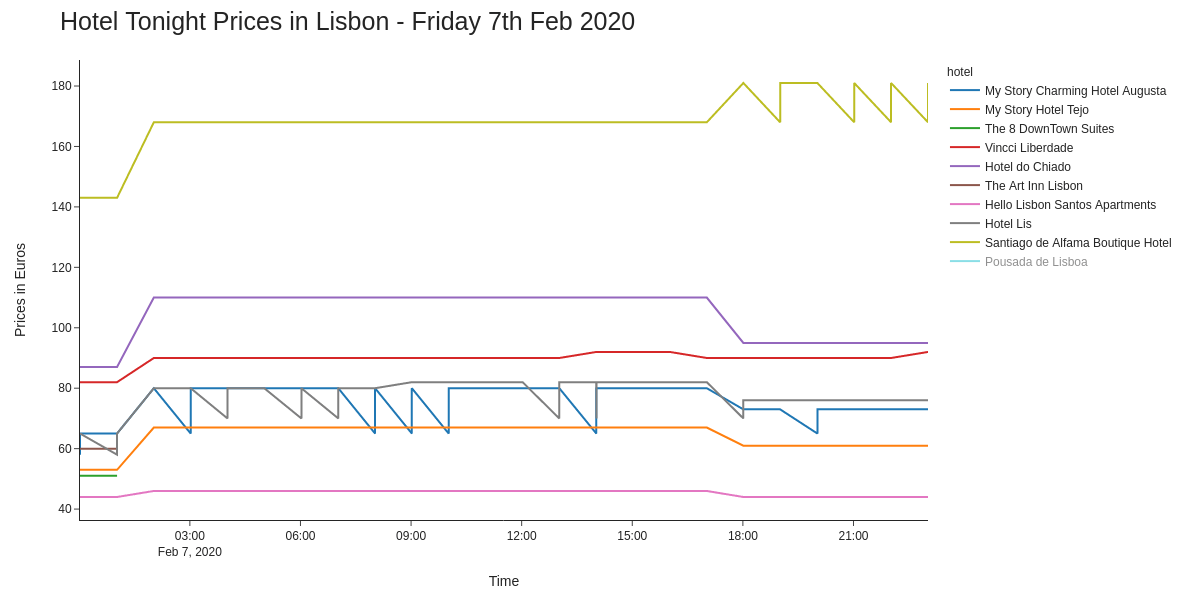
It looks like my hypothesis holds for some of the hotels, yet others seem to have algorithmic pricing - at least it looks like that to me, particularly with the zig-zag pricing during the night. However, to cut a long story short it looks like it’s worth waiting til past 6pm local time, when the revenue manager finishes their shift and hopes to come to work the following day with a higher RevPAR :)
Prices at most hotels appear to drop at least €10 by 6pm - that’s 4 large beers in Lisbon!
In the future I might look at different cities, and also collect data over a vaster period of time - but for now I’ll go and have one of those 4 large beers I’ll save next time I book a hotel.